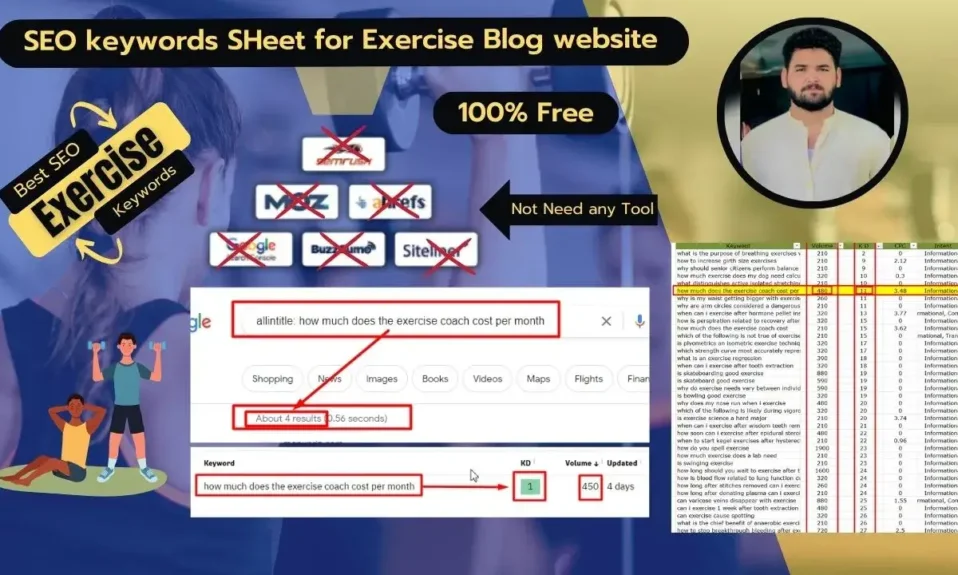


In case you are on the lookout for the reply to the query “Why isn’t Google indexing my web page”, you must deal with understanding the causes of this example. There is perhaps loads of them! This text examines three major indexing points and presents 14 potential causes that may result in them.
How do you make certain why your web site will not be on Google?
There are numerous the explanation why your web site might not present up in Google search outcomes. Earlier than you’re taking any motion, it’s essential to grasp the reason for your indexing troubles. You are able to do so by utilizing the next three strategies.
- Google Search Console (GSC) – a free software offered by Google that incorporates numerous instruments and experiences. A few of these will mean you can test your web site’s indexation.
- ZipTie.dev – a software that means that you can test indexation utilizing a sitemap crawl, an URL listing, or a crawl of your total web site. It additionally means that you can schedule a recrawling of your pattern, so you may simply monitor the indexation.
- “Website:” command – you may test in case your web page has been listed by utilizing the “web site:” command in Google search. Sort “web site:yourdomain.com” into the search bar, changing “yourdomain.com” along with your web site’s URL.
This can present you a listing of pages that Google has listed. Watch out although! Utilizing search operators doesn’t provide the full image and this methodology won’t present all pages.
14 the explanation why your web site will not be listed by Google
Let’s check out the most typical the explanation why pages are usually not listed by Google. Possibly one in all them applies to your state of affairs.
Your web page wasn’t found
Which means that Google was unable to search out the web page on the web site. When Google will not be capable of uncover a web page, it can’t be listed and won’t seem within the search outcomes. There are three foremost the explanation why Google may wrestle to search out your web page.
Your web page isn’t linked internally
Inner hyperlinks play an important position in a web site’s indexation by serps like Google. When serps’ bots crawl a web site, they comply with hyperlinks to find and index new pages. Inner hyperlinks, that are hyperlinks that join pages inside the identical web site, assist robots like Googlebot navigate a web site and perceive its construction.
If a web site lacks inside hyperlinks, serps’ bots might have problem discovering all of its pages, and this may end up in some pages not being listed.
Need to know extra? Take a look at our Ultimate Guide to Internal Linking in SEO!
Your web page will not be within the sitemap
A sitemap is a file that lists a web site’s most vital indexable pages (or all of them in some circumstances). Search engine robots can use this file to find and index the web site’s content material.
When a web page will not be included within the sitemap, it doesn’t imply that it received’t be listed by serps. Nonetheless, not together with a web page within the sitemap could make it more durable for search engine robots to find and crawl it. If a web page will not be included within the sitemap, it might be perceived as much less vital or decrease within the hierarchy. In some circumstances, this example may end up in some pages not being found, even with inside linking in place.
Then again, together with a web page within the sitemap will help serps in two methods. It’s simpler to find the web page, and its presence within the sitemap serves as a clue that this explicit web page is vital and needs to be listed.
Discover out extra by studying our article: Ultimate Guide to XML Sitemaps for SEO!
Your web site is simply too massive and you must wait
When Googlebot crawls a web site to index its content material, it has a restricted period of time to take action. When a web site is each massive and to make issues worse, gradual to load, crawling it will probably current a problem for search engine bots. Because of this, robots like Googlebot could also be unable to index all pages inside the given time restrict. This may trigger points on your web site as a result of any pages that aren’t listed don’t seem within the search outcomes and don’t work on your web site’s visibility.
Be taught extra about crawling by our article: The Beginner’s Guide to Crawling
Your web page wasn’t crawled
When bots crawl a web site, they uncover new pages and content material that may be added to Google’s index. This course of is crucial to make sure that pages are seen within the search outcomes. Nonetheless, if a web page isn’t crawled, it received’t be added to the search engine’s index. There are a number of the explanation why a web page won’t be crawled by a search engine; these embrace a low crawl funds, errors, or the truth that the web page is disallowed in robots.txt.
These articles might assist you to with this downside:
Your web page is disallowed in robots.txt
The robots.txt file is a textual content file used to instruct search engine robots which pages or directories on their web site to crawl or to not crawl. Web site admin. can optimize the robots.txt to point out serps which content material needs to be accessible to crawl.
As a basic rule, if a web page is disallowed within the robots.txt file, search engine bots shouldn’t be capable of crawl and index that web page. Nonetheless, there are exceptions to this. For instance, if a web page is linked from an exterior useful resource, it will probably get listed regardless that it’s blocked in robots.txt. One other frequent mistake is treating robots.txt as a software to dam indexing. When you disallow the web page in robots.txt, it is going to prohibit Googlebot from crawling it, but when a web page was listed earlier than – it is going to stay listed.
Nonetheless – more often than not, the web page won’t be accessible for crawling and indexing in case you block it in robots.txt. And in case you uncover that your web page wasn’t crawled in any respect, it is perhaps since you unintentionally blocked it with a robots.txt file.
In case you are undecided what to do on this state of affairs, be at liberty to achieve out to an website positioning specialist who will be capable to assist.
Discover out extra:
Your crawl funds is simply too low
The crawl funds refers back to the variety of pages or URLs that Google’s bots will crawl and index inside a given timeframe. When the crawl funds allotted to a web site is simply too low, it signifies that the search engine’s crawler received’t be capable to crawl and index all of the pages immediately. Which means that a number of the web site’s pages might not present up within the search outcomes.
It is a simplified definition, however in case you’d prefer to be taught extra – try our information:
Bear in mind which you could have an effect in your crawl funds. It’s sometimes decided by the search engine based mostly on a number of elements. There are numerous issues that will negatively have an effect on your crawl funds, the most typical being:
- too many low-quality pages
- an abundance of URLs with non-200 standing codes or non-canonical URLs
- gradual server and web page velocity
When you consider your web site has points with the crawl funds, it’s best to attempt to discover the reason for this example. An skilled website positioning Specialist will certainly assist you to with that.
Server error prevents Googlebot from crawling
When Googlebot tries to crawl an online web page, it sends a request to the server internet hosting the web site to retrieve the web page’s content material. If the server encounters a difficulty, it is going to reply with a server error code, indicating that it couldn’t present the requested content material. Googlebot interprets this as a short lived unavailability or as a difficulty with the web site; this may decelerate crawling.
Because of this, a few of your pages will not be listed by the search engine. Moreover, if this occurs repeatedly and the web site retains returning constant server errors, it’d result in pages getting dropped from the index.
In case your web site has vital server issues, you may evaluation these points in one in all GSC’s experiences.
Extra data and suggestions on the way to repair that downside:
If you wish to test how explicit standing codes (together with server errors) have an effect on Googlebot’s conduct, you may study it in Google’s official documentation: How HTTP status codes, and network and DNS errors affect Google Search.
Google didn’t index your web page or deindexed it
If Google doesn’t index a web page or deindexes a beforehand listed one, the web page received’t seem within the search outcomes. It may be attributable to technical issues, low-quality content material, guideline violations, and even guide actions.
Your web page has a noindex meta tag
If a web page on a web site has a noindex meta tag, it instructs Google to not index the web page. Which means that the web page won’t seem within the search outcomes.
In some situations, meta tags might inadvertently be set to “noindex, nofollow” as a consequence of a improvement error. Consequently, the web page might get faraway from the index. If that is later mixed with a robots.txt blockade, a web page won’t get crawled and listed once more. In some circumstances, it is perhaps supposed and may very well be an answer to some form of index bloat challenge. Nonetheless, we suggest being extraordinarily cautious with any actions that will disturb crawling and indexing.
Learn our articles and learn to do away with pointless noindex:
Your web page has a canonical tag pointing to a unique web page
A canonical tag on a web site’s web page instructs serps to deal with the canonical URL as the popular URL for that web page’s content material. This tag is used when the web page’s content material is a replica or variation of one other web page on the location. If the canonical tag will not be carried out appropriately, it will probably trigger indexation points.
You may be taught extra about canonical tags in our article:
For the aim of this text, please keep in mind that all unique pages ought to have a self-referencing canonical tag. A web page may find yourself not getting listed if it has a canonical to a different URL.
Your web page is a replica or close to duplicate of a unique web page
When a web page on a web site is a replica or close to duplicate of one other web page, it will probably trigger indexation and rating points. If a web page is a replica of one other one, Googlebot might not index it. And even when such a web page is listed, serps normally won’t enable duplicate content material to rank properly.
Duplicate content material can even have an effect on a web site’s crawl funds. Googlebot must crawl every URL to establish if they’ve the identical content material, which may eat extra time and sources. Because of this, Googlebot has much less capability for crawling different, extra priceless pages.
Whereas there isn’t a particular “duplicate content material penalty” from Google, there are penalties associated to having the identical content material as one other web site. Actions resembling scraping content material from different websites or republishing content material with out including extra worth are usually not welcome on the earth of website positioning, and will even harm your rankings.
Do you wrestle with duplicate content material? Take a look at our information to repair it:
The standard of your web page is simply too low
Google goals to supply the very best person expertise by rating pages with high-quality content material increased in search outcomes. If the content material on the web page has poor high quality, Google might not contemplate it priceless to customers and will not index it. Moreover, poor-quality content material can result in a excessive bounce charge, which is when customers rapidly depart the web page with out interacting with it. This may sign to Google that the web page is irrelevant or not priceless to customers, leading to not indexing it.
Your web page has an HTTP standing apart from 200 (OK)
The HTTP standing code is a part of a response {that a} server sends to a consumer, after receiving a request to entry a webpage. The HTTP standing code 200 OK signifies that the server has efficiently responded to the request, and the web page is accessible.
If a web page returns an HTTP standing code apart from 200 OK, it received’t get listed. As for why, it is dependent upon the actual standing code. For instance, a 404 error standing code signifies that the requested web page will not be discovered, and a 500 error standing code signifies that there was an inside server error. If Googlebot encounters these errors whereas crawling a web page, it might assume that stated web page will not be accessible or not purposeful, and it’ll not index it. And if a non-200 HTTP standing code persists for a very long time, a web page could also be faraway from the index.
Your web page is within the indexing queue
When a web page is within the indexing queue, it signifies that Google has not but listed it. This course of can take a while, particularly for brand spanking new or low-traffic web sites, and it may be delayed additional if the web site has technical points, a low crawl funds, or robots.txt blockades and different restrictions.
Moreover, if the web site has plenty of pages, Google might not be capable to index all of them directly. Because of this, some pages might stay within the indexing queue longer. It is a frequent downside which can get resolved with time, but when it doesn’t – it is perhaps needed to investigate it additional and take motion.
Google couldn’t render your web page
When Googlebot crawls a web page, it not solely retrieves the HTML content material but in addition renders the web page like a browser does. If Googlebot encounters points whereas rendering the web page, it might not be capable to correctly perceive the content material of the web page. If Google can’t render the web page, it might not be capable to establish sure components, resembling JavaScript-generated content material or structured knowledge, which are vital for indexing and rating.
As Google admits of their article Understand the JavaScript SEO basics:
“If the content material isn’t seen within the rendered HTML, Google received’t be capable to index it.”
In some circumstances, this could have an effect on the indexing of the URL. If a big a part of your web page isn’t rendered, it received’t be seen to Google. A web page like this can probably be thought of a replica or low high quality, and will find yourself not getting listed.
Learn extra about this subject:
Your web page takes too lengthy to load
Typically, when purchasers ask us “why isn’t Google indexing my web page” the reply is {that a} web page takes too lengthy to load. That is perhaps additionally your case!
If Googlebot is crawling a web site that hundreds slowly, it might not be capable to crawl and index all the pages on the location inside the allotted crawl funds.
Furthermore, web site loading velocity is a vital issue that may impression person expertise and search rankings – so it’s undoubtedly a crucial a part of web site optimization.
The way to get listed by Google
In case your web site is totally new, it might take a while earlier than it’s absolutely listed. We suggest ready a couple of weeks and monitoring the state of affairs with instruments like Google Search Console or ZipTie.dev.
If that’s not the case and your web site has ongoing issues with indexing, you may comply with these steps:
- Begin by figuring out the basis explanation for the issues utilizing our listing of potential elements.
- As soon as the trigger is recognized, make the mandatory fixes.
- In any case modifications are carried out, submit the web page once more in Google Search Console.
In case your actions don’t deliver the supposed outcomes, contemplate in search of the help of knowledgeable technical SEO agency.
Wrapping up
When you’re experiencing indexing points and your pages aren’t displaying up on Google, it’s best to examine the basis causes behind this. If you wish to discover the reply to your query – “why isn’t Google indexing my web page” such evaluation needs to be a crucial first step.
Trying to repair the difficulty with out figuring out the causes of indexing issues is unlikely to achieve success, and will even deliver extra hurt than good.
Nonetheless, some indexing points may be fairly advanced and troublesome to deal with in case you don’t have sensible expertise on this space. If the documentation we offered on this article will not be sufficient, it’s advisable to hunt assist from knowledgeable technical SEO agency to make sure that the difficulty is resolved successfully.
#isnt #Google #indexing #web page #causes